There is one facility inside SAS Enterprise Miner (EM), however, that is becoming very popular in relieving the condition. The feature, the usage of Score Node and Reporter Node together, has actually been within EM for a long time.
The picture below shows a moderately elaborate EM model project
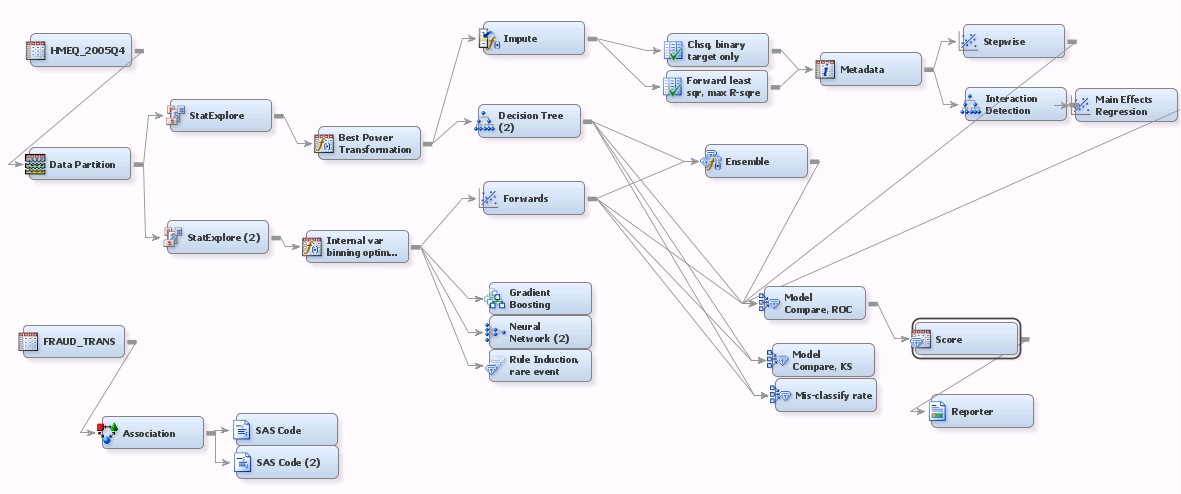
- EM's Score node is listed under Assess tool category. While it normally performs SCORING activities, the goal of the scoring exercise in this flow context is NOT towards score-production. On the contrary, scoring here is often towards validation (especially one-off scoring on ad hoc testing data files for the model), profiling and, YES, reporting. Reporting is where this regulatory task falls under.
- You can link the Score to a model, or Model Comparison node as indicated by the picture above.
- The picture below shows how to click through to get to the Score node

Once the Score node is connected to a preceding model or Model Comparison node, you can click on the Score node to activate the configuration panel as shown below

- For this reporting task, you can ignore details underneath Score Code Generation section.
- The selections under Score Data are important, but that is if you have partitioned the model data set into validation or test data set or both. You typically have at least one of them for regulatory reporting exercise.
- You can test and see what are underneath the Train section.
Below shows how you click through to introduce the Reporter node to the flow.

After you introduce the Reporter node and connect it to the Score node, the configuration panel, the core focus of this blog, appears upon clicking the node
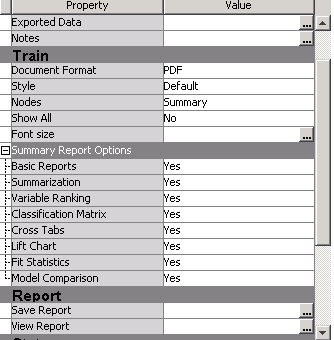
- As of today, two Document formats are supported, PDF and RTF. RTF is a draft format for Word. Given that the direct output from EM Reporter node typically is used/perceived as a great starting pointing, subject to further editing using Word, not a final version, RTF format is more popular than PDF. Of course, if you prefer using Adobe for editing you can use PDF
- There are four styles available, Analysis, Journal, Listing and Statistical. +four Nodes options, Predecessor, Path, All and Summary. So far, the most popular combination among banks is Statistical /Path.
- Selecting Show All does produce much more details. The resulting length of the document can easily exceed 200 pages.
- You can configure details under Summary Report Options to suit your case. It is very flexible.
- This is how EM works: when you add nodes to build model, say, add EDA nodes like transformation and imputation, EM automatically records transformation and imputation, or 'actions'. When you connect a Score node, the Score node picks up all the details along the path (therefore the option Path or All Path), compile them into score code and flow code. The score code, in SAS data step, SAS programs (meaning procedures), (for some models) C, Java and PMML, is then available for production. When you add the Reporter node, EM will report on the process details.
To sum, the biggest advantage of using the Score +Reporter combination in EM is to provide one efficient, consistent starting model documentation template. Consistent because now if you ask the whole modeling team to report using the same set of configuration options, you get the same layout, granular details and content coverage. That is a big time saver.
Thank you.
From Wellesley, MA