This post is one of several upcoming posts I plan to
publish soon that discuss code mapping of key analytical data
exercises from traditional SAS programming to SASIMSH. This post today covers
using PROC IMSTAT to transpose data.
Prior to IMSTAT being available, SAS users typically either write data step code or engage PROC transpose to transpose data. In PROC IMSTAT, PROC transpose is not supported (of course, because there is no way another procedure is supported to run underneath and within a procedure like PROC IMSTAT, or any SAS procedure. There is no statement in PROC IMSTAT to explicitly do what PROC transpose does either). However, PROC IMSTAT CAN be programmed to transpose. This post provides one such example.
Code part 1: Set up in-memory analytics SAS libraries for Hadoop + loading
Below is code part 1 screen shot
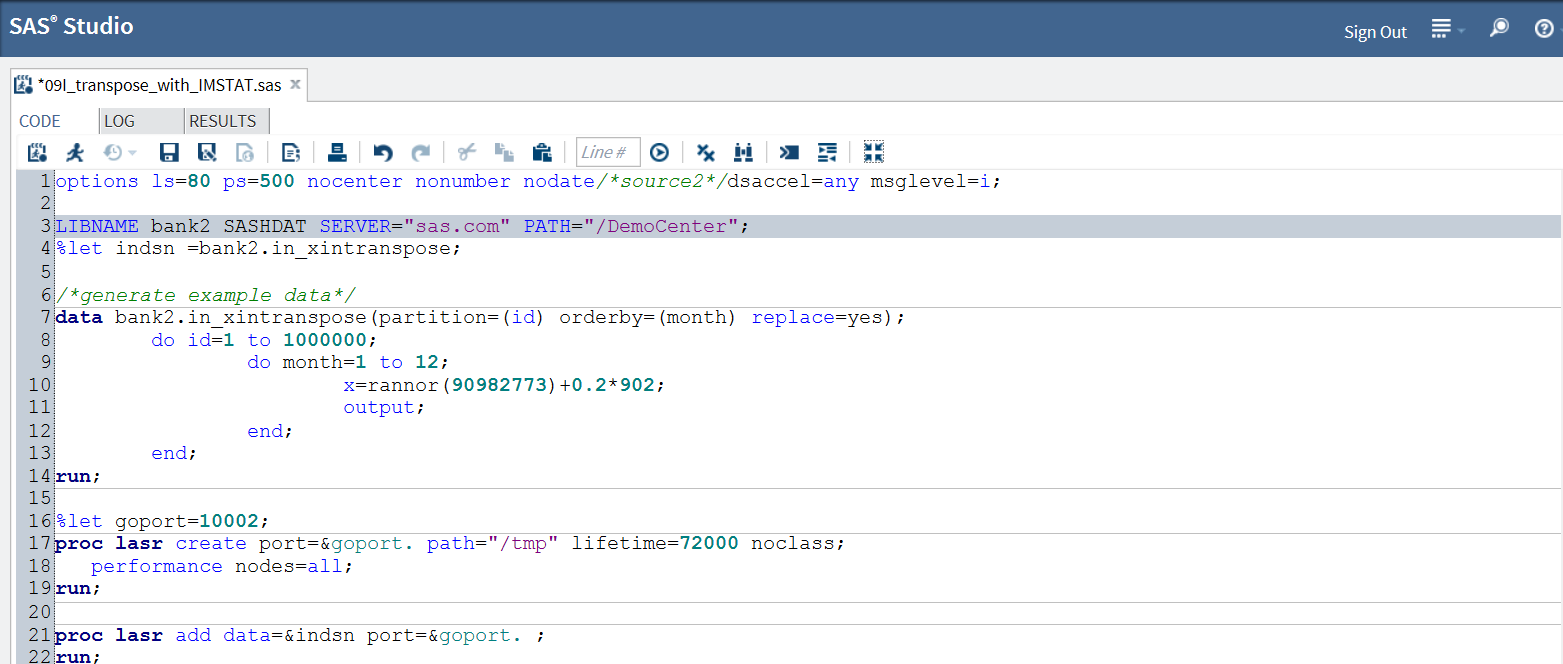
- The first LIBNAME statement sets up library reference to a Hadoop cluster by the IP address of sas.com (I cleaned up confidential address info), which I am using 14 parallel nodes out of >180 nodes in total.
- At this design interface, the analyst (me) does not care if the underlying Hadoop is Cloudera or Horton Works or somebody else. IMSTAT is designed NOT to program differently simply because the underlying Hadoop is 'from a different flavor of Hadoop'. Bank2 is the name for the SAS library, as if you are just setting one up for regular SAS work or access to Oracle, Green Plum DB or Teradata DB. The naming convention is the same.
- SASHDAT is the quintessential differentiator for SAS in-memory advanced analytics. It appears just like regular SAS Access driver. It actually is, but much more in the interest of enabling genuine in-memory analytics; somebody can write a book about this 'driver' alone. For now, it simply allows us to enable SAS in-memory data access onto Hadoop.
- Path= is a directory management structure, little new.
- From the DATA statement,
- I am simulating 12 months of variable X data for 1 million IDs. Simple.
- I am asking SAS to write the 12 million rows directly to Hadoop in the SASHDAT format. In doing so, I also request that the resulting data set &indsn be sorted by ID (the partition= data set option) and further sorted by MONTH (orderby=). The fact with 'sorting' in a parallel system like this, though, is that sorting (with the partition= option) is actually grouping: sorting by ID actually is just placing records with the same ID values together; they do not collate any more (meaning sequencing groups in descending or ascending value of the variable ID like BASE SAS is doing with PROC SORT) . Since later access to the grouped records will be parallel, why spending more time and resources ( a lot if your data set is huge) asking them to further collate after initial grouping? Orderby= option is to add collation WITHIN grouped groups. The notion of using partition= AND orderby= is the same with "PROC SORT; by ID month;", but the physiology and mechanism of the act is different, moving from a 'single server' mode to parallel world (or from SMP to MPP)
- Also, the partition and orderby options are supported as data set options (in a typical MPP Hadoop operation as such, likely these two data set options are only supported at output data sets, not at input data set. Why?), whereas in regular BASE SAS operation, the analyst has to call up separate PROC SORT to do it. This luxury is affordable now because this is IN-MEMORY, this is no longer disk swapping (Imagine more and you will enjoy this more, I promise)
- The Replace=: this is Hadoop finger print. If the destination library is set up to point to other DB such as ORACLE or Teradata, or any DBMS-like, this option does not work. As Hadoop is towards more 'managed' (not necessarily towards DBMS, but Yarn, Kerberos...) this may or may not change. Not shown here, but I recall another option is Copy=. The Copy option simply tells Hadoop how many copies it should make for the data set you are dumping into its laps.
- At "PROC LASR",
- This block is creating one in-memory working session by requesting allocation of port 10002 (if available at the time I submit the request) as "access, passing lane" to the server, by requesting directory "/tmp" as "operating/temp parking ground'.
- Lifetime =: tells IMSTAT that after 72000 seconds, trash the whole session and everything within it. Noclass=: not required, has something to do with categorical variable loading
- Performance nodes=ALL: means all Hadoop nodes that are available and policy-permitted by whoever is in charge of the 'box'
- The second "PROC LASR" has ADD option asking that the table I wrote to the target Hadoop cluster be loaded into the memory session I just created. As you may learn more and more about 'loading data into memory', this is only one of many loading methods. The analyst, for example, certainly can load many SAS7BDAT data sets sourced by all kinds of traditional venues and practices (PROC SQL, BASE...) by using another in-memory engine SASIOLA. There are also data loader products from SAS as well. Once the table is loaded into memory, it parks there until the server is terminated.
- Notice: this session implicitly inherits the server from previous lines, if not directed or specified otherwise. The port, however, must be explicit while trying to load data into it. The session is port specific and the port is generic: port number 10002 means the same to whoever is using it.
Code Piece 2: Reference the loaded file in-memory, build code to transpose
Below is code part 2 screen shot

- The LIBNAME TRANS engages SASIOLA engine to call up the file just loaded into the memory space by pointing to the directory where the in-memory session is set up. This LIBNAME statement uses tag= option to represent this reference for later processing. This tagging act is to respond to the fact Hadoop system typically has system of directories, which is worsen by the fact Hadoop systems often run off Linux-like OS which per se has limitless directories. Traditionally SAS products support two levels such as mysas.in. Tagging therefore is in place.
- The "PROC FCMP" portion is entirely my doing that does not much to generalize. I show how one can generate code in this way. You can certainly type or copy to make your own reference code file.
- The ARRAY details in the middle of FCMP should be straightforward. I am sure you can make it more sophisticated, implicit (or mysterious). The point is to show one basic approach to transpose data with IMSTAT. Noteworthy is the __first_in_partition and __last_in_partition. This is nothing but your familiar first.ID and last.ID. Their invocation certainly depends on the data set being partitioned/sorted (where did it happen in this post? Did it already happen?)
Code Piece 3: Using PROC IMSTAT to tranpose/score the data
Below is code part 2 screen shot
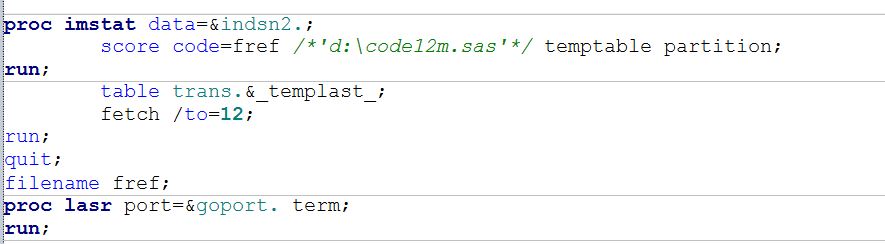
As many SAS users often say, the last piece is the easiest. Once the code is built, you can run it through the SCORE statement. To use the __first_in_partition and __last_in_partition, you MUST specify partition option value at the SCORE statement. In this way, IMSTAT will go search for the partition table created while partition= and orderby= options were effected (this certainly is not the only way to partition and order). FETCH is similar "PROC PRINT".
The last "PROC LASR" with TERM is to terminate the in-memory session once the job is done. This is one important habit to have with SAS LASR centered in-memory analytics, although not a technical requirement. Lengthy discussion on this subject belongs to another post.
Here are some log screen shots
 |
| Generating 12 Million Records, 3 Variables, 14 Seconds |
 |
| Load 12 Million Records, 3 Variable to Memory, 2.6 Seconds |
 |
| Transposing takes 5 Seconds |
| TRANSPOSED ! |
October 2014, from Brookline, Massachusetts
Thanks for sharing this valuable information to our vision. You have posted a trust worthy blog keep sharing.
ReplyDeleteRegards,
sas training institute in Chennai
The information provided was extremely useful and informative. Thanks a lot for useful stuff..
ReplyDeleteCMMI Consulting in Chennai
This comment has been removed by the author.
ReplyDeleteNice Information Big Data Hadoop Online Training
ReplyDelete